
全国卫生组织(WHO)的东谈主工智能健康资源助手 SARAH 列出了旧金山本不存在的诊所的空虚称号和地址。
Meta 公司“夭殇”的科学聊天机器东谈主 Galactica 虚构握造学术论文,还生成对于天外熊历史的维基著述。
本年 2 月,加拿大航空被敕令投诚其客户职业聊天机器东谈主握造的退款计策。
昨年,又名讼师因提交充满空虚法则见解和法律援用的法庭文献而被罚金,这些文献皆是由 ChatGPT 编造的。
如今,大讲话模子(LLM)胡编乱造的例子已层见错出,但问题在于,它们异常擅长一册矜重地瞎掰八谈,编造的内容大部分看起来皆像是果真,让东谈主难辨真假。
在某些情况下,不错当个乐子一笑而过,然而一朝触及到法律、医学等专科限度,就可能会产生异常严重的后果。

若何有用、快速地检测大模子的幻觉(hallucination),已成为现时国表里科技公司和科研机构竞研究注的热点策划标的。
如今,牛津大学团队忽视的一种新要领便省略匡助咱们快速检测大模子的幻觉——他们尝试量化一个 LLM 产生幻觉的进度,从而判断生成的内容有多忠于提供的源内容,从而种植其问答的准确性。
策划团队暗示,他们的要领能在 LLM 生成的个东谈主简介,以及对于琐事、知识和生命科学这类话题的讲述中识别出“编造”(confabulation)。
该策划兴致要紧,因为它为检测 LLM 幻觉提供了一种通用的要领,无需东谈主工监督或特定限度的知识。这有助于用户了解 LLM 的局限性,并激动其在各个限度的运用。
研究策划论文以“ Detecting Hallucinations in Large Language Models Using Semantic Entropy ”为题,已发表在泰斗科学期刊 Nature 上。
在一篇同期发表的“新闻与不雅点”著述中,皇家墨尔本理工大学算计机本领学院院长 Karin Verspoor 教育指出,该任务由一个 LLM 完成,并通过第三个 LLM 进行评价,就是在“以毒攻毒”。
但她也写谈,“用一个 LLM 评估一种基于 LLM 的要领似乎是在轮回论证,况兼可能有偏差。”不外,作家指出他们的要领有望匡助用户阐述在哪些情况下使用 LLM 的讲述需要夺目,也意味着不错种植 LLM 在更多运用场景中的真确度。
若何量化 LLM 的幻觉进度?
咱们先来了解一下,大模子的幻觉是若何产生的。
LLM 的缱绻初志是生成新内容。当你问聊天机器东谈主一些问题时,它的讲述并不是一起从数据库中查找现成的信息,也需要通过大皆数字算计生成。
这些模子通过预测句子中的下一个词来生成文本。模子里面有成千上亿个数字,就像一个雄壮的电子表格,纪录了词语之间的出现概率。模子老到进程中束缚调遣这些数值,使得它的预测适应互联网海量文本中的讲话模式。
因此,大讲话模子本体上是证据统计概率生成文本的“统计老虎机”,摇杆一动,一个词便出现了。
现存的检测 LLM 幻觉的要领大多依赖于监督学习,需要大皆的标注数据,且难以泛化到新的限度。
在这项策划中,策划团队使用了语义熵的要领,该要领无需标注数据,且在多个数据集和任务上发扬出色。
语义熵(semantic entropy)是一种估量讲话模子生成的文本中潜在语义不细目性的要领,通过考虑词语和句子在不同落魄文中的兴致变化来评估模子预测的可靠性。
该要领能检测“编造”(confabulation)——这是“幻觉”的一个子类别,专指不准确和精真金不怕火的内容,常出当今 LLM 枯竭某类知识的情况下。这种要领考虑了讲话的高明分裂,以及讲述若何能以不同的情势抒发,从而领有不同的含义。
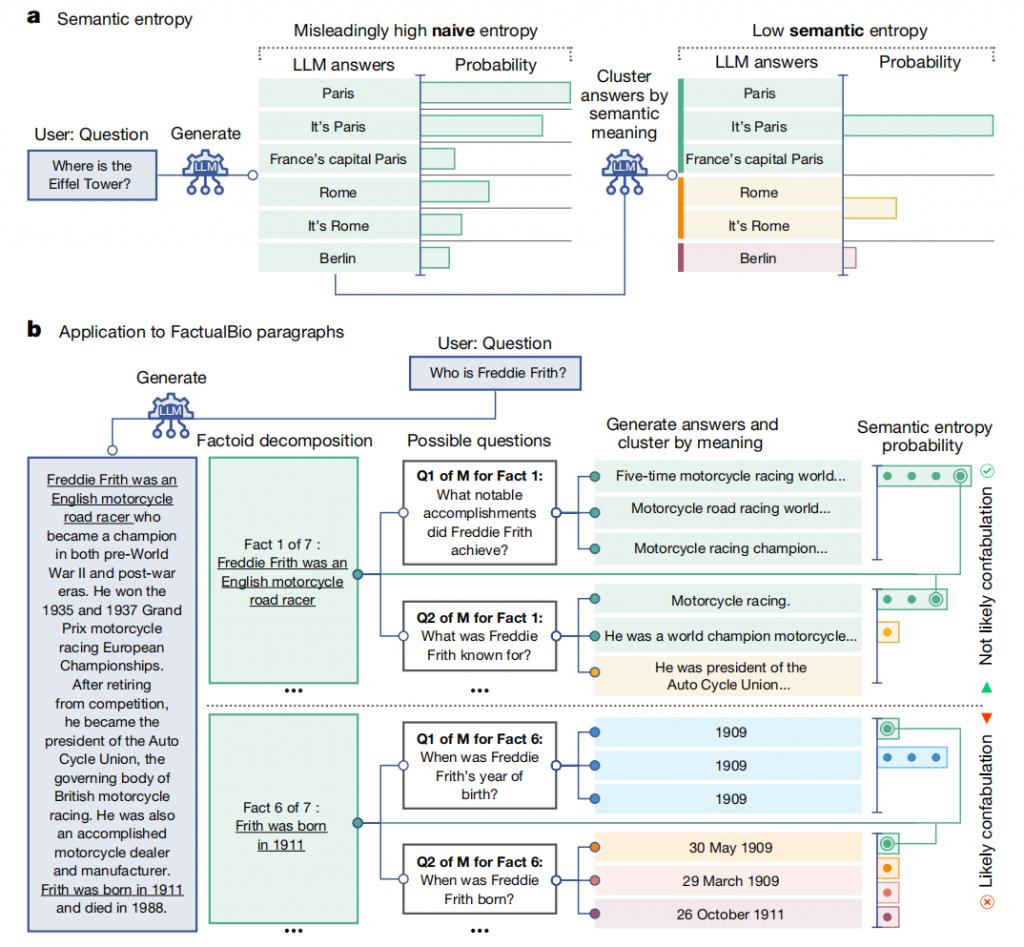
图|语义熵与虚构内容检测简述
如上图所示,传统的基于熵的不细目性度量在精准谜底的识别上存在局限,举例,它将“巴黎”、“这是巴黎”和“法国的皆门巴黎”视为不同谜底。关联词,在触及讲话任务时,这些谜底虽表述不同但兴致换取,这么的措置情势明显不适用。语义熵要领则在算计熵之前,先将具有换取兴致的谜底进行聚类。低语义熵意味着大讲话模子对其内容含义具有很高的细目性。
另外,语义熵要领还能有用检测长段落中的虚构内容。策划团队领先将生成的长谜底解析为些许小事实单位。随后,针对每个小事实,LLM 会生成一系列可能与之研究的问题。然后,原 LLM 会为这些问题提供 M 个潜在谜底。接着,策划团队算计这些问题谜底的语义熵,包括原始的小事实自己。高平均语义熵标明与该小事实研究的问题可能存在虚构因素。在这里,由于即使用词相反权臣,但生成的谜底闲居传达换取兴致,语义熵奏效将事实 1 分类为非虚构内容,而传统的熵要领则可能忽略这少量。
策划团队主要在以下两个方濒临比了语义熵与其他检测情势的分裂。
1. 检测问答和数学问题中的虚构内容
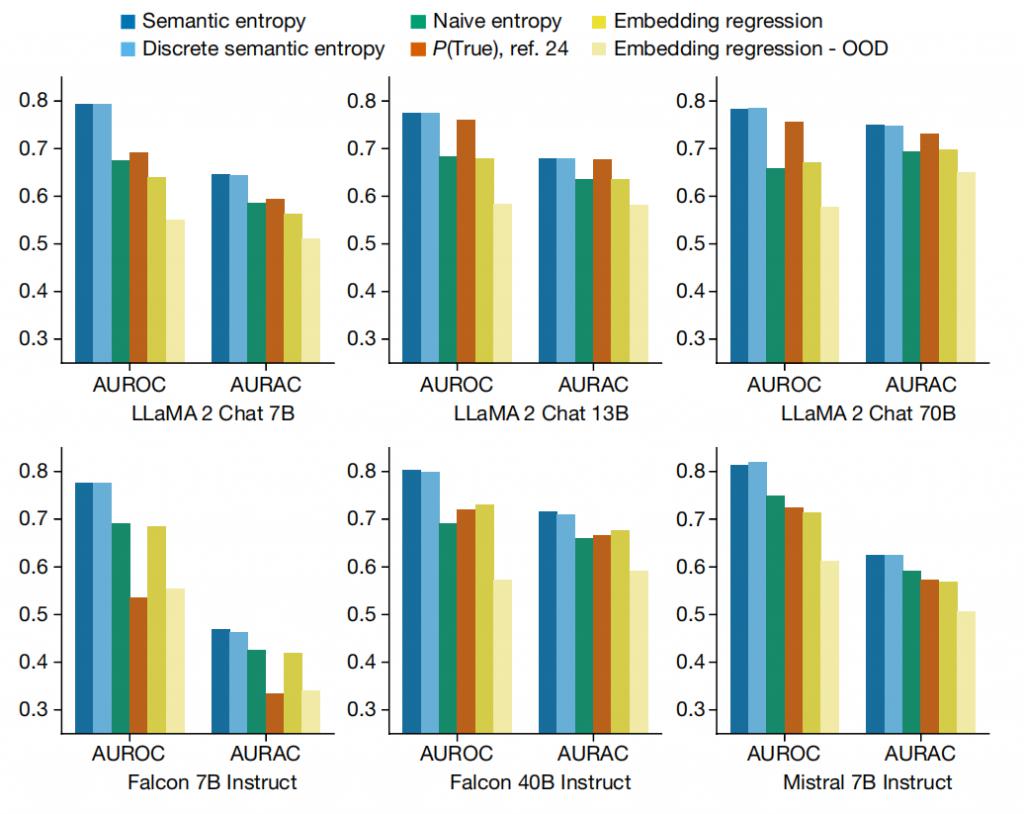
图|检测句子长度生成中的虚构内容。
从上图中不错看出,语义熵优于整个基线要领。在 AUROC 和 AURAC 两个想法上,语义熵均展现了更好的性能,这标明其省略更准确地预测 LLM 空虚,并种植模子阻隔讲述问题时的准确率。
2. 检测列传中的虚构内容
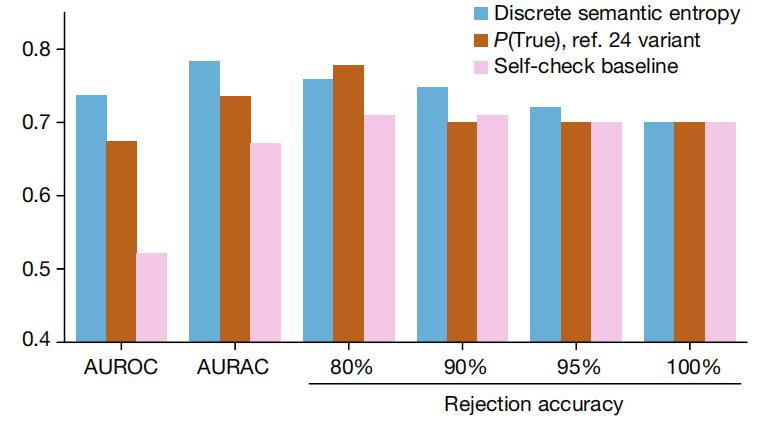
图|检测段落长度列传中的 GPT-4 虚构内容。
如上图所示,语义熵臆想器的破碎变体在 AUROC 和 AURAC 想法(在 y 轴上得分)上均优于基线要领。AUROC 和 AURAC 皆彰着高于两个基线。在讲述进步 80% 的问题时,语义熵的准确性更高。唯独当阻隔最有可能是虚构内容的前 20% 谜底时,P ( True ) 基线的剩余谜底准确性才好于语义熵。
不及与瞻望
策划团队忽视的概率要领充分考虑了语义等价性,奏效识别出一类要津的幻觉表象——即由于 LLM 知识枯竭而产生的幻觉。这类幻觉组成了现时开阔失败案例的中枢,且即便模子智商接续增强,由于东谈主类无法全面监督整个情境和案例,这类问题仍将接续存在。虚构内容在问答限度中尤为隆起,但相通在其他限度也有所体现。
值得夺想法是,该策划使用的语义熵要领无需依赖特定的限度知识,预示着在详细雅致等更多运用场景中也能赢得雷同的进展。此外,将该要领彭胀到其他输入变体,如重述或反事实情状,不仅为交叉检查提供了可能,还通过辩护的形势完毕了可彭胀的监督。这标明该要领具有无为的适用性和纯真性。语义熵在检测空虚方面的奏效,进一步考证了 LLM 在“知谈我方不知谈什么”方面的后劲,本体上可能比先前策划所揭示的更为出色。
关联词,语义熵设檀越要针对由 LLM 知识不及导致的幻觉,比如系风捕影或张冠李戴,对于其他类型的幻觉,比如由老到数据空虚或模子缱绻残障导致的幻觉,可能恶果欠安。此外,语义聚类进程依赖于当然讲话推理用具,其准确性也会影响语义熵的臆想。
往日,策划东谈主员但愿进一步探索语义熵要领在更多限度的运用,并与其他要领相麇集,从而种植 LLM 的可靠性和真确度。举例,不错策划若何将语义熵要领与其他本领,比如与抵抗性老到和强化学习相麇集,从而进一步种植 LLM 的性能。此外,他们还将探索若何将语义熵要领与其他想法相麇集,从而更全面地评估 LLM 的真确度。
但需要咱们意志到的是,只消 LLM 是基于概率的,其生成的内容中就会有一定的立时性。投掷 100 个骰子,你会得到一个模式,再投一次,你会得到另一个模式。即使这些骰子像 LLM 一样被加权来更时常地生成某些模式,每次得到的纵容仍然不会统统换取。即使每千次或每十万次中唯惟一次空虚,当你考虑到这种本领每天被使用的次数时,空虚的数目也会尽头多。这些模子越准确,咱们就越容易平缓警惕。
对于大模子的幻觉,你何如看?
参考贵府:
|点击存眷我 难忘标星|